
この記事は、TeX & LaTeX Advent Calendar 2015 の第 6 日目のために書いたものです。
12/5 のご担当は neruko3114 さんで、12/7 のご担当は 515hikaru さんです。
XeTeX や LuaTeX をバリバリお使いの方からすると、「なんで今どき tfm なんて作る必要あるの ? !」 と思われるでしょうけれど、私は怠け者なため、まだ fontspec パッケージの使い方をちゃんと理解していないので、ついつい昔ながらの方法に頼ってしまいます。
…というような書き出しを考えていたところ、思いもかけないことに今年の重点テーマが 「今さら人に聞けない、TeX のキホン」 となったので、「今さら人に聞けない otftotfm のキホン」 とか 「今さら人に聞けない tfm とリガチャのキホン」 といった言葉が一瞬頭をかすめましたが、結局そんな大それたタイトルを掲げる勇気はありませんでした。
otftotfm は、(欧文の) OpenType フォントを元に、LaTeX で使うのに必要な tfm や vf、enc、map などを生成してくれるツールで、LCDF Typetools に含まれているもののひとつです。LCDF Typetools は、
cfftot1, mmafm, mmpfb, otfinfo, otftotfm, t1dotlessj, t1lint, t1rawafm, t1reencode, t1testpage, ttftotype42
から成っていて、W32TeX にも TeX Live にも収録されているのではないかと思います (これらのうちで私が使ったことがあるのは、cfftot1, otfinfo, t1dotlessj, otftotfm, t1testpage くらいです)。
ちなみに、otftotfm で “--no-type1” オプションを付けないと、内部で cfftot1 が呼ばれ、また、元になる OpenType フォントに dotlessj がない場合に “--no-dotlessj” オプションを付けてないと、t1dotlessj が呼ばれます (つまり、デフォルトでは、OpenType が PostScript Type1 に変換された上、dotlessj 用の tfm や pfb も自動生成されてしまいます)。
otftotfm の使い方についての情報は既にたくさんあって、例えば:
などがとても参考になりますので、本記事では基本的な使用法については繰り返しません。
それで、LaTeX で普通に OT1 や T1、LY1 とかで使うというのであれば、話は簡単です。
でも、OT1 や T1 というのは TeX 界特有のエンコーディングで、勝手な想像ですけれど、OT1 は、Knuth 先生が英語で数学の論文を書くのに必要なグリフを集めたもので、T1 のほうは、ヨーロッパの言語を扱うために必要なグリフは何かという観点から構成されていて、いずれも、既存の PostScript Type1 とか TrueType とかに当該グリフが含まれているかどうかというのは、あまり重要視されなかったのではないかと思われます (ないのなら METAFONT で作ればいいわけですから !)。そのため、TrueType や OpenType には何百、何千ものグリフが収録されているにも関わらず、OT1 や T1 をすべて埋めることができるフォントというのは、あまり多くないようです。
他方、LY1 は、Type1 のフォントに含まれているグリフを LaTeX で使うためのエンコーディングなので、Type1 のフォントを利用する分には効率的な構成とはいえますが、でも、TrueType や OpenType のフォントには、LY1 に収められているよりもたくさんのグリフが入っているので、それらにアクセスしたいなと思います。
新たにフォントを入手するといつも、t1testpage を使って収録されているグリフの一覧を見てみるのですけれど、OT1、T1、LY1 に含まれていないグリフで使ってみたいものは、各種リガチャや、異体字、あとは long-s とかでしょうか。
TrueType や OpenType には何百、何千ものグリフが入っているとはいっても、tfm という太古の技術に依拠する限りは、ひとつの tfm に収めることができるグリフ数は 256 個までという制約があります。T1 (ec.enc) にはまったくスロットの空きがなく、LY1 (texnansi.enc) だと空きが 5 スロット、そして LY1 内部の重複を削った texnansx.enc だと、20 スロット空いています。
otftotfm では “-f” オプションを使ったり基底 enc の空きスロットにグリフ名を直接書き足したりすることでグリフの追加が可能なので、基底エンコーディングとして texnansx.enc を利用すれば、20 個までは好きなグリフを追加することができることになります。
うーん、20 個か…。T1 なんかだと、一度も使ったことないし使う予定もないグリフがいっぱい入っているので、それらをザックリ削った自分用の enc を作ってそれを基底エンコーディングに使うという手もあるかも知れません (あと、もちろん OT1 なら 128 スロット空いてはいますけれど、せっかくの OpenType フォントなのに diacritical mark 付きの文字がみんな合成グリフになってしまうのでは、あまりうれしくありません)。
ということで、だいぶ前置きが長くなりましたが、今回のテーマは:
otftotfm を使って、OpenType フォントに含まれているグリフで、T1 や LY1 には入っていない各種リガチャや異体字を利用できるようにすること。ついでに、リガチャにする場合としない場合を使い分けられるようにしたりとか、あと、異体字への自動的な切り替えにもトライしてみようかと思います。
次のような順番で話を進めます:
Since: December 5, 2015.
以下の例はいずれも、一旦 t1testpage で全グリフを出力してみて、それを眺めて私が興味をもったグリフを、適当に抜き出したものです。
まずは、「24 時間以内 399 セット限定 75 % off !」 という宣伝文句につられて買ってしまった MagmaII から使えそうなグリフを拾ってみますと:
a、g、l、E、I、J、& が 2 デザインずつ入ってますね。リガチャは f の一般的なリガチャのみですが、“fi” と “fl” は、昔ながらの “/fi” “/fl” という名前と、“/f_i” “/f_l” の両方がカバーされています。
次は、これまた 77 % off の誘惑に負けてつい買ってしまった Palatino の 3 ファミリー (Palatino nova, Palatino Sans, Palotino Sans Informal) の中から、Palatino Sans の例です:
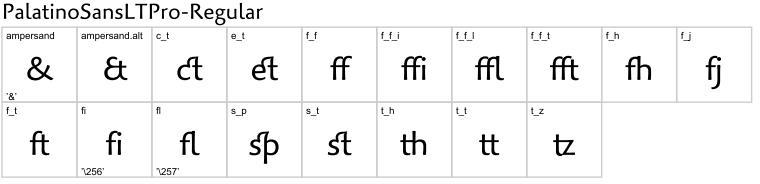
& が 2 デザインあって、あとは、f のリガチャの他に t のリガチャもあり、また、ct, et, sp, st もリガチャになっています。
続いては、2013 年 3 月に Linotype が Monotype へと社名変更した際にフリーで配布してくれた 6 書体の中から、ITC Galliard を見てみます:
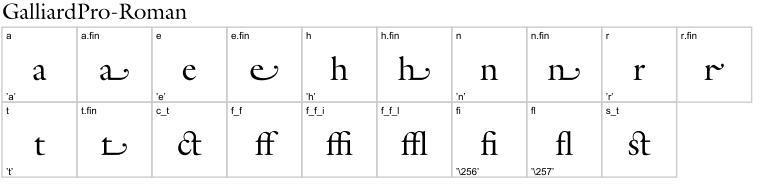
a、e、h、n、r、t に語末用のグリフが用意されていて、あとは、一般的な f のリガチャの他に ct と st がリガチャになっています。
あれ ?、これまでのところですと、どれも 20 スロットの空きがあれば間に合う感じですかね…。
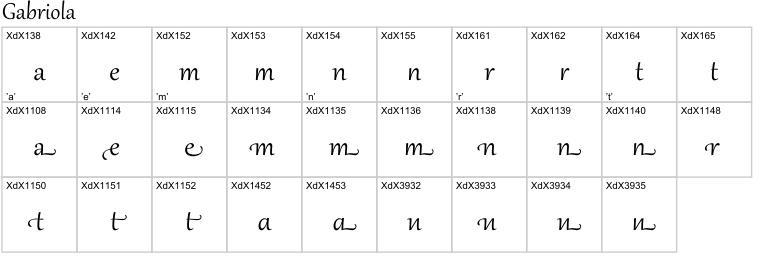
今の ITC Galliard には語末用のグリフが入ってましたが、手書き風な書体の場合には、語頭や語末のためのグリフが用意されていることがあります。リガチャもたくさん入っているフォントの例として、Windows にバンドルされている Gabriola を見てみましょう。
まずは、a、e、m、n、r、t のバリエーションです (適当に拾ったので、本当はもっとあるかと思います):
次に f のリガチャです (もっとたくさんあるのですけど、面倒なので diacritical mark が付いてないようなものだけを大体拾ったつもりです):
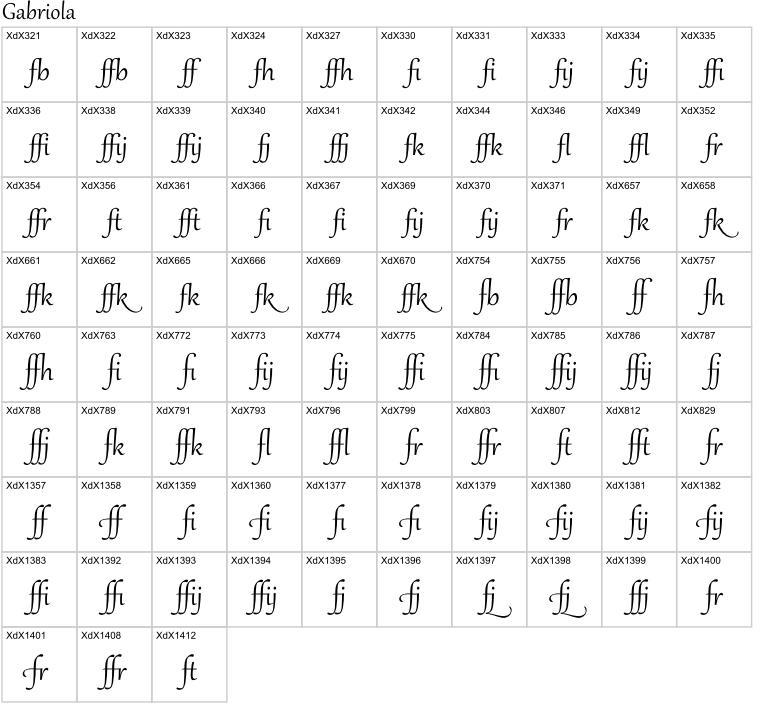
さすがにこんなには要りませんよね…。
最後に、もうちょっと実用的なものとして、EB Garamond を見てみます:
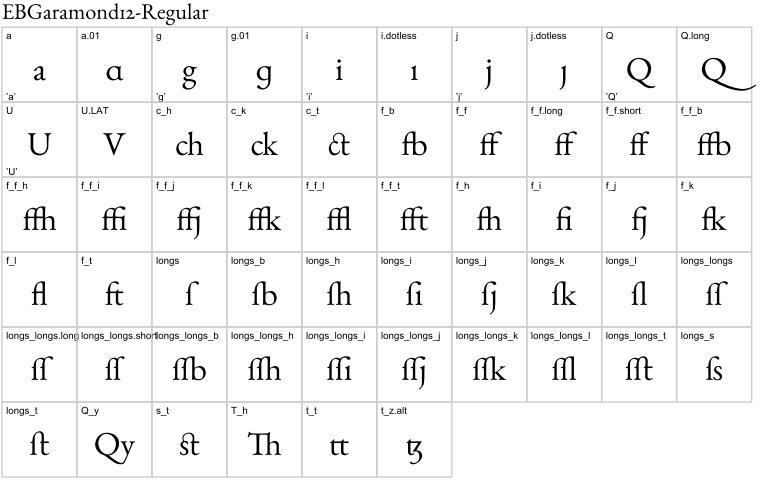
long-s のリガチャも豊富に含まれてて、空きスロットが 20 ではすべてのリガチャにアクセスするのは無理ですね (となるとやっぱり fontspec か…)。
さてさて。
今見たようなグリフたちを LaTeX で使えるようにするにはどうしたらいいのかというと、otftotfm を利用しながらも地道にやるとするならば、基底の enc ファイルに使いたいグリフの名前 (ないしユニコード) とそのグリフのリガチャの指定とを書き加えることになるのだと思います (リガチャの設定は “--ligkern” オプションでの追加も可)。
例えば、“et” というリガチャが使いたいのであれば、基底 enc ファイルの空いているスロットに “/e_t” と書いた上で、リガチャの設定 “% LIGKERN e t =: e_t ;” を書き足してから otftotfm で tfm を作ればよさそうです (異体字についても、例えば “% LIGKERN E asterisk =: E.alt ;” みたいにしてリガチャとして実現可能)。
でも、基底の enc ファイルに直接手を加えなくとも、ある程度のことは otftotfm が自動でやってくれます。“-f” というオプションで OpenType の feature を指定すると、対応するグリフが追加されて、リガチャの設定も自動的に tfm に追加されます。
otftotfm のマニュアルには、“-f” オプションに指定できる OpenType の feature が約 30 載っています (aalt, c2sc, calt, case, cpsp, cswh, dlig, dnom, fina, frac, hist, kern, liga, lnum, numr, onum, ordn, ornm, pnum, salt, sinf, size, smcp, ss01--ss20, subs, sups, swsh, tnum, zero)。
なお、上のほうで何度か 「“-f” オプションでグリフを追加」 と書きましたが、“-f” オプションに指定できる feature のうち、その指定によってグリフが追加されるものは、実はそんなに多くはないです。例えば、“-fkern” は、OpenType のカーニングペアを tfm の LIGTABLE に書き入れるオプションですし、“-fliga” は、リガチャの設定を tfm の LIGTABLE に書き込み、“-fc2sc” は、/a, /b, /c, ... を /a.sc, /b.sc, /c.sc, ... に置き換えるオプションですので、これらを指定したところで必ずしもグリフが 「追加」 されるわけではありません。
個人的には、使えたらうれしいなと思う feature は、calt, salt, fina, hist; dlig, liga; cswh, swsh; kern くらいでしょうか。lnum, onum, pnum, tnum は数字の feature ですけれど、まぁ、onum が用意されているフォントなら、これも使えるといいかな。
数字のスタイルの組み合わせというのもちょっと面倒ですよね…。Lining で Tabular にするか Proportional にするか、それとも Oldstyle で Tabular にするか Proportional にするか、を選ばないといけないので。
それぞれの OpenType フォントでどの feature が用意されているのかは、“otfinfo -f” で確認することができます。
例えば、さっき見た ITC Galliard の場合には、
aalt Access All Alternates c2sc Small Capitals From Capitals case Case-Sensitive Forms dlig Discretionary Ligatures dnom Denominators dpng <unknown feature> frac Fractions kern Kerning liga Standard Ligatures lnum Lining Figures numr Numerators onum Oldstyle Figures ordn Ordinals pnum Proportional Figures salt Stylistic Alternates sinf Scientific Inferiors smcp Small Capitals ss01 Stylistic Set 1 sups Superscript tnum Tabular Figures
という情報を得ることができます。
グリフの一覧と照らし合わせてみて、“/c_t” とか “/s_t” のリガチャを追加するオプションは “-fdlig” で、“/a.fin” “/e.fin” 等々を追加するには “-fsalt” かな、と一応推測できますけれど、フォントによっては、実際に指定してみないと、どの feature がどのグリフに対応しているのか分からないこともあります (← 私だけ ? !)。
例えば、EB Garamond の場合、同梱されている Specimen.pdf の “2 FEATURES” の “2.7 LIGATURES” によりますと、“liga” で f のリガチャと long-s のリガチャとが有効になり、“hlig” で st, ct, sp, sk のリガチャが有効になる (後二者はイタリックの場合のみ) とのことです。
それで、実際に試してみましたところ、「“/c_t” とか “/s_t” のリガチャを追加するオプションが “-fdlig”」 なのは当たってましたが、“-fsalt” のほうは、“/a” や“/e” を “/a.fin” “/e.fin” に置き換えるオプションでした…。ありゃ。
また、“-fdlig” を指定すると、“ct” や “st” は (“c{}t” 等と書かない限りは) 必ずリガチャになってしまいますが、これも、普段はリガチャにはせずに、リガチャにしたいときだけリガチャにできたほうが使い勝手がいいような気がします。
ここで、“/a” や“/e” を “/a.fin” “/e.fin” に置き換えるのではなくて、“/a.fin” “/e.fin” 等を追加して、両者を使い分けたり、リガチャについても、リガチャにする ・ しないの制御をしたいのですが、そのための方法が、otftotfm にはちゃんと用意されています。
“--altselector-char=char” というオプションがあって、このオプションに文字ないしスロットの番号を指定すると、異体字の使い分けや、リガチャの制御が可能になります (基底の enc ファイルに “% LIGKERNX ^^ = char ;” と書いて指定しても同じです)。altselectorchar をどの feature に対して有効にするのかは、“--altselector-feature=feature” で指定しなければならないとのことですが、デフォルトで “salt” と “dlig” は有効になっているらしいです。
実はこの辺りの関係はよく分かってません。“salt” と “dlig” については、“--altselector-feature=” の指定が必要ない、というだけのことかと思ったのですが、実際には、altselectorchar を設定すると、“-fsalt” や “-fdlig” の指定をしなくとも、“salt” や “dlig” が有効になっています。
具体的には、例えば、“--altselector-char=*” とするか、基底 enc に “% LIGKERNX ^^ = 42 ;” と書くかすると、“a*” で “/a.fin” にアクセスできて、リガチャも、“ct” ではリガチャにならずに “c*t” と書くと “/c_t” になるという風に使い分けができるようになります。
試しに、ITC Galliard を元にして、
--no-type1 --no-dotlessj -e 7t --altselector-char=*
というオプション指定で生成したファイル群を使って、glyph table と
a e h n r t ct st aa* ee* hh* nn* rr* tt* c*t s*t
とを出力してみますと、こんな感じになります:
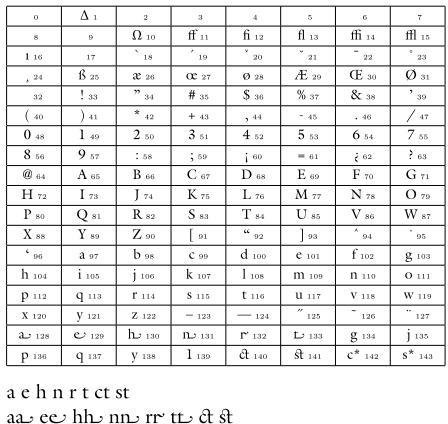
texnansx.enc の 20 個の空きスロットは飛び飛びなので、ここでは追加されたグリフが分かり易いように、基底の enc として OT1 の 7t.enc を使いました。また、グリフを確認したいだけなので -fkern 等も省略しています。ITC Galliard には /dotlessj は入っておらず、“--no-dotlessj” を指定しているので 17 番のスロットは空になっています。0 番と 2〜9 番の OT1 のグリフも ITC Galliard には入ってないので、空です。
そして、OT1 は 127 番までですので、128 番以降が、otftotfm が追加したグリフです。 altselectorchar を設定しているお蔭で、“dlig” と “salt” が有効になっています (ITC Galliard で “-fdlig”,“-fsalt”,“--altselector-char” を同時に指定するには 16 スロットの空きが必要ということもこれで分かります.なお、字形の違いが顕著でないので上掲 1. の例では挙げてませんでしたが、134〜139 番も ITC Galliard に含まれている異体字です)。
142 番と 143 番がちょっと面白くて、vf を介して “c” と “*”、“s” と “*” がそれぞれ合成されています。結局、altselectorchar もリガチャの仕組みを利用しているわけで、tfm の設定を確認すると、“a” と “*” のリガチャを “a.fin” にしていて、また、“c” と “*” のリガチャを一旦 “c*” にしてから “c*” と “t” のリガチャを “c_t” としていることが分かります。
これで、単語末の a、e、h、n、r、t では、“*” を添えれば、語末用の異体字が利用できるようになりました。でも、もしも、単語末で、自動的に語末用の異体字に切り替わるようにできたら、もっと便利ですよね。リガチャの仕組みと boundarychar というのを利用すると、これが可能になります。
いま、さらりと 「tfm の設定を確認すると、…が分かります」 と書きましたけれど、TeX では実は、リガチャの設定は tfm でされています。他にも、上のほうで 「基底 enc ファイルにリガチャの設定 “% LIGKERN e t =: e_t ;” を書き足して」 云々なんてことも言いました。
また、otftotfm のマニュアルの “ENCODINGS” という節にも、
LIGKERN comments in the encoding can add ligatures and inhibit kerns, as in afm2tfm (1). To add a ligature, say:
% LIGKERN glyph1 glyph2 =: result ;
The "=:" operator indicates a normal ligature, where both the input glyphs are removed and replaced by result. To preserve the left-hand glyph, for an effect like "glyph1 glyph2 =: glyph1 result", use "|=:" instead; to preserve the right-hand glyph, use "=:|".
とか、
% LIGKERN || = boundarychar ; % LIGKERNX ^^ = altselectorchar ;
という説明があって、“LIGKERN” とか “boundarychar” という用語も当たり前のように出てきます (“LIGKERNX” は otftotfm が独自に導入したものです)。
でも、これらって、tfm やリガチャの仕組みについてある程度の基礎知識がないと、何のことやら分かりませんよね…。
それで、何を読めばいいのか今回少し調べてみたのですが (私自身そんなに昔からのユーザーじゃないので !)、次の 3 点がいいんじゃないかと思います:
リガチャの指定方法が増えたり、“boundarychar” が導入されたのが TeX Version 3 からだったらしく、一つ目の記事ではそれらが説明されています。また、tfm はバイナリなので、編集する際には tftopl で pl ファイルに変換して、逆に pl は pltotf で tfm に変換できるのですが、二つ目はその pltotf のマニュアルです。そして、otftotfm のマニュアルから引用した部分には、enc ファイルの LIGKERN の働きが afm2tfm に準じていると書かれていますけれど、afm2tfm は dvips に付属のツールなので、その説明は三つ目の dvips のマニュアルにあります。
なのであとはこれらを読んでください、で済ませるのではあんまりなので、以下、私が理解している範囲で簡単に説明を試みてみます。
tfm を pl に変換して中を覗いてみますと、最初のほうに “LIGTABLE” というものがあって、そこに、リガチャとカーニングの設定が書かれています。
例えば、pltotf のマニュアルに載っている例をうんと簡単にしたもので考えてみますと:
(LIGTABLE
(LABEL C f)
(LIG C f O 200)
(KRN O 51 R 1.5)
(/LIG C ? C f)
(STOP)
)
みたいな感じになっています。
“(LABEL C f)” と “(STOP)” の間の部分が、文字 f に対してのリガチャとカーニングの設定を表わしていて、この文字 f については、(LIG C f O 200)、(KRN O 51 R 1.5)、(/LIG C ? C f) の三つの設定がなされています (実際の pl ないし tfm ではもっとたくさんの文字についての設定が “
ここで、“C” は Character (文字)、“O” は Octal (8 進表記)、“R” は Real (実数) を表わしているので、“C f”、“C ?” は 「文字 f」 と 「文字 ?」 の意味で、“O 200”、“O 51” は文字コードが 「8 進数で 200 番目 (の文字)」 と 「8 進数で 51 番目 (の文字)」、そして “R 1.5” は、(pl の冒頭に書かれている “DESIGNSIZE” と “DESIGNUNIT” の値の比の) 「1.5 単位分」 ということを表わしています。
この例では、8 進数で 200 番目の文字は “ff” というリガチャだということにしてあって、8 進数で 51 番目の文字は “右の閉じ括弧 〔 ) 〕” であると仮定されています。
それで、一つ目の (LIG C f O 200) という設定は、文字 f の次に文字 f が続いた場合には、両者を取り除いた上で、8 進数で 200 番の文字すなわち “ff”に置き換えるということを表わし、二つ目の設定 (KRN O 51 R 1.5) は、文字 f の次に 8 進数で 51 番の文字すなわち右の閉じ括弧が続いた場合には、1.5 単位空ける、ということを表わしています。
リガチャについては、TeX Version 2 までは、ある特定の文字とある特定の文字が連続した場合には、両者を取り去って別の文字に置き換える、という設定の “LIG” しかなかったらしく、
(LABEL ●) (LIG ▲ ■)
と書くと、● ▲ → ■ ということになるのですが、TeX Version 3 からは、連続した 2 文字の一方または両方を残す、というような設定も可能になったとのことです。
つまり、
(LABEL ●) (/LIG ▲ ■)
と書くと、左を残して ● ▲ → ● ■ となり、
(LABEL ●) (LIG/ ▲ ■)
と書くと、右を残して ● ▲ → ■ ▲ となり、そして、
(LABEL ●) (/LIG/ ▲ ■)
と書くと、両方を残して ● ▲ → ● ■ ▲ となります。
なお、一方または両方を残して置き換えをする場合には、その結果が 2 文字 (● ■ とか ■ ▲) ないし 3 文字 (● ■ ▲) になりますが、 (これらの組み合わせに対してリガチャやカーニングが予め設定されていると) これらに対しても更に、リガチャやカーニングが働きます。
したがって、上の例では、三つ目の設定 (/LIG C ? C f) は 「文字 f の次に文字 ? が続いた場合には、左の文字 f を残して文字 f と置き換える」 ということなので、まず、f ? → f f となります。 しかし、続いて、一つ目の設定で、文字 f については、次に文字 f が続いた場合にはリガチャ “ff” に置き換えるとされているので、結局、f ? は最終的にはリガチャ “ff” に置き換わることになります。
この、置き換え後の更なるリガチャやカーニングの処理を抑制したい場合には、/LIG>、LIG/>、/LIG/>、/LIG/>> のように書きます (“>” は、一回置き換えをしたら、すぐ右へ進め、って意味かな ?)。
例えば、f ? f の 3 文字が連続した場合を考えてみます。上のような設定であれば、今みましたように、最初の f ? が 2 段階の処理を経てリガチャ “ff”に置き換わるので、最終的には、リガチャ ff と、f 、という並びになります。
しかし、もしも三つ目の設定が、(/LIG C ? C f) ではなく、(/LIG> C ? C f) であったとしますと、f ? f の 3 文字は、まず最初の f ? が f f になりますが、この 2 文字に対する更なる処理は抑制されているので、f f は、f と f のママで、f f f という並びになります。そして、次に、2 文字目と 3 文字目の f が、リガチャ “ff”に置き換わるので、最終的には、f と、リガチャ ff、という並びになります。
pl ファイルを直接編集して tfm 内のリガチャやカーニングの設定を変更する場合には、以上のような規則にしたがって “LIGTABLE” を書き変えることになります。
それに対して、afm2tfm を使って tfm を作成する場合には、afm2tfm に読み込ませる enc ファイル中の、
% LIGKERN ;
というコメント行にリガチャやカーニングの設定を書き込むと、生成される tfm の “LIGTABLE” にそれらが反映されるようになっています (ここではカーニングについては割愛します)。
pl ファイルの LIGTABLE における、
LIG /LIG /LIG> LIG/ LIG/> /LIG/ /LIG/> /LIG/>>
というリガチャの指示は、afm2tfm の enc ファイルでは、
=: |=: |=:> =:| =:|> |=:| |=:|> |=:|>>
という書式になります (METAFONT における記法を踏襲しているらしいです)。
なお、試してはいないのですがマニュアルを見る限りでは、otftotfm に読み込ませる基底 enc ファイルの場合には、これらのうちの、“=:”、“|=:”、“=:|” の三つしか使えないかも知れません。
“boundarychar” も TeX Version 3 で導入された新機能とのことです。つまり、現在の TeX は、単語の両端に、目に見えない “boundary character” というものがあると考えているのだそうです。
この boundary character を利用すると、単語の語頭や語末において、リガチャやカーニングを行うことが可能になります。例えば、語頭においては、“左の boundary character” と語頭の文字とのリガチャ、語末においては、語末の文字と “右の boundary character” とのリガチャを設定することによって、語頭や語末のグリフを自動的に変更することができるようになるわけです。
pl ファイルの LIGTABLE においては、“左の boundary character” については、ちょうど文字 “f” の設定が “(LABEL C f)” から “(STOP)” までだったのと同じようにして、“(LABEL BOUNDARYCHAR)” から “(STOP)” までの部分で、リガチャやカーニングの設定を行うことができます:
(LIGTABLE
(LABEL BOUNDARYCHAR)
(/LIG C a C A)
(/LIG C b C B)
(/LIG C c C C)
(STOP)
)
この例は、語頭が a のとき (boundarychar + a) は A に置き換え (→ boundarychar + A)、b のときは B に、c のときは C に置き換える、ということを示しています。
“右の boundary character” をリガチャやカーニングで利用する場合には、LIGTABLE より前で、BOUNDARYCHAR にコードを与えます:
(BOUNDARYCHAR O 40)
(LIGTABLE
(LABEL C d)
(LIG/ O 40 C D)
(STOP)
(LABEL C e)
(LIG/ O 40 C E)
(STOP)
(LABEL C f)
(LIG/ O 40 C F)
(STOP)
)
“(BOUNDARYCHAR O 40)” の部分で “BOUNDARYCHAR” に 8 進数で 40 というコードを与えているので、これによって、LIGTABLE では、“O 40” で、“右の boundary character” を表わすことができるようになります。
つまり、今の例では、文字 d の次が “右の boundary character” のとき (つまり語末のとき) には D に置き換え、e のときは E に、f のときは F に置き換えることになります。
ちなみに 8 進数で 40 (10 進数で 32) というコードには、大抵の場合 /space が割り当てられていますが、TeX はスペースを使わないので、“右の boundary character” に与えるコードとしては、しばしばこの番号が利用されます。
pl ファイルを直接編集する場合は、以上のようになりますが、afm2tfm や otftotfm を利用する場合には、これらに読み込ませる enc ファイルで boundarychar の設定をします。
enc ファイルでは、boundarychar を “||” で 表わすので、今の 2 つの例を enc ファイルで設定する場合には、次のようになります:
% LIGKERN || = 32 ; % LIGKERN || a |=: A ; % LIGKERN || b |=: B ; % LIGKERN || c |=: C ; % LIGKERN d || =:| D ; % LIGKERN e || =:| E ; % LIGKERN f || =:| F ;
でも、これは afm2tfm だとうまくいくのですけれど、実は、otftotfm では半分しかうまくいきません。
afm2tfm の enc の場合は、“||” にコードを設定してもしなくても、“|| a |=: A ;” のような “左の boundary character” の設定は、LIGTABLE の “(LABEL BOUNDARYCHAR)” の部分に正しく反映されます。
ところが、otftotfm の enc の場合には、“||” にコードを設定しないで “|| a |=: A ;” のように書くと、
otftotfm: ./Foo.enc:1: warning: '||' has no encoding, ignoring ligature
と言われてしまいます (ここで Foo.enc は、読み込ませている基底 enc です)。そこで、“|| = 32 ;” のように boundarychar にコードを与えてみると、今度は “左の boundary character” の設定が、LIGTABLE の “(LABEL O 40)” の部分に書き込まれてしまって、結局 “左の boundary character” としては機能しません。
なので、otftotfm の場合には、boundarychar は、コードを与えた上で “右の boundary character” として使うもの、と割り切るか、それとも、“左の boundary character” が必要ならば、otftotfm が生成する tfm や vf を pl や vpl に変換して “(LABEL O 40)” の部分を手作業で “(LABEL BOUNDARYCHAR)” に書き直すことになります。
以上 (a) (b) から、otftotfm の enc では、“=:”、“|=:”、“=:|” と “右の boundary character” しか使えないかも知れないのですが、単語末で語末用のグリフに自動で切り替える分には、これで十分です。
ITC Galliard で語末用のグリフが用意されているのは、a、e、h、n、r、t なので、これらの文字と、単語末の次に続く文字とのリガチャを設定すれば、単語末で自動的に語末用のグリフに切り替えられそうです。
単語の終端の目印となるものとしては、“右の boundary character” の他に、“, 〔/comma〕”、“. 〔/period〕”、“: 〔/colon〕”、“; 〔/semicolon〕”、“? 〔/question〕”、“! 〔/exclam〕”、“ ) 〔/parenright〕”、“ ] 〔/bracketright〕” などが考えられます。各種引用符の閉じ側でも単語末になりますが、引用符の向きは言語によって異なるので、今回は考慮しないことにします。
otftotfm に読み込ませる基底 enc ファイルで altselectorchar を 42、boundarychar を 32 とした上で、a、e、h、n、r、t についてリガチャの設定をします。例えば a についての設定は次のようになります:
% LIGKERN a || =:| a.fin ; % LIGKERN a comma =:| a.fin ; % LIGKERN a period =:| a.fin ; % LIGKERN a colon =:| a.fin ; % LIGKERN a semicolon =:| a.fin ; % LIGKERN a question =:| a.fin ; % LIGKERN a exclam =:| a.fin ; % LIGKERN a parenright =:| a.fin ; % LIGKERN a bracketright =:| a.fin ;
残りの文字についても同様にリガチャの設定を追加した enc ファイルを用いて otftotfm で作成したファイル群を使ってみますと、
aa, aa. aa: aa; aa? aa! aa) aa] \par ee, ee. ee: ee; ee? ee! ee) ee] \par hh, hh. hh: hh; hh? hh! hh) hh] \par nn, nn. nn: nn; nn? nn! nn) nn] \par rr, rr. rr: rr; rr? rr! rr) rr] \par tt, tt. tt: tt; tt? tt! tt) tt] Lorem ipsum dolor sit amet, consec*tetuer adipiscing elit. Ut purus elit, ves*tibulum ut, placerat ac, adipiscing vitae, felis. Curabitur dic*tum gravida mauris. Nam arcu libero, nonummy eget, consec*tetuer id, vulputate a, magna.
という入力から、以下が得られます:

うまくいったようです。
なお、今回は、私の手持ちの OpenType フォントで、語末用のグリフが収録されているものとして、ITC Galliard を例に使ってみましたが、この ITC Galliard の語末用のグリフのデザインは、本当は、すべての単語の語末に使うようなものではなくて、行末とか、段落末の単語の語末に使うものなんじゃないかと思います。
同じような方法で、long-s を持っているフォントの場合に、/longs と /s を自動で切り替えることもできると思われます。
otftotfm の “-f” オプションで “hist” を指定するのでは、単に /s が /longs に置き換わるだけなので、小文字の s が全部 long-s になってしまって、それではうれしくないです。そこで、“-fhist” オプションを使うのではなくて、手作業で、基底 enc の /s を /longs に書き換えて、また、空いているスロットに /s を書き足した上で、上掲の a と同様に “% LIGKERN longs || =:| s ;” 等々のリガチャの設定も行えば、通常の小文字の s は /longs になって、単語末では /s になるようにできるはずです。
ちなみに、リガチャの仕組みを使って /longs と /s とを自動で切り替えるというやり方は、何ら目新しいものではなくて、もう随分と前に、本田さんの s-yfonts パッケージ (2001 年) とか永田先生の s-dayroman パッケージ (2006 年) で実用化されてたみたいです。
冒頭でも述べましたように、XeTeX や LuaTeX をお使いのみなさんには、こんな古 (いにしえ) の知識なんて必要ないかもしれません。
fontspec パッケージを使いこなせるようになれば、こんなことができるんだ!、と驚かされた例として Raphaël Pinson さんという方が EB Garamond を使って 1564 年刊のフランス語の聖書を再現したものがあります:
[オリジナル (画像)] [再現例 (画像)] [ソース]
あ゛ーっ、どなたか 「今さら人に聞けない fontspec の *すべて*」 とか、書いてくださらないかな…。
それと、最後の最後に、話がちょっとズレちゃいますけど、この聖書では、本文の両脇に、1、2、3、… と a、b、c、… の二系統の註釈が付いていますけれど、昔の法律書なんかだと、註釈に更に註釈が付いているようなもの もあったりします。いつの日かこんな複雑な組み方も LaTeX で再現できるようになるのかなぁ…。
それでは、Merry TeXmas & Happy TeXing!
Since: December 5, 2015.